When the topic of executing hidden code comes up, one's mind often goes into techniques like process injection, C2 server shenanigans, polymorphic code, etc. But what if I tell you there is a method that can execute code that lies plain and simple in the binary, but you'll never see it?
Before we get started on the juicy stuff, I'm afraid we'll need to learn some prerequisites first. If you happen to be an expert in the .NET compilation and runtime process, and also know how to read assembly, then I have some great news for you: you can skip past a bunch of stuff I'm about to talk about and jump right into Reversing it (although I'd appreciate you giving it a read for the 3 cans of chocolate milk that went into making this post).
Okay, so let's jump right into it.
# What is .NET?
Essentially, .NET is simply a framework developed by Microsoft. Early on, they realised that having different kinds of languages across different kind of platforms was going to get real messy real soon, so they decided to have a common ground for all of them to exist and thrive on: .NET.
It helps to think of it as an abstraction layer. Developers don't have to bother about what platform they're writing their programs for (hardware/software, OS, graphics, optimisation, etc.), they can focus on writing good software, and if that software is capable of running on the .NET framework on one device, it is more than likely it will run on all other devices as well (where .NET is installed, of course). Everything from the different languages to the runtime engine - all come under .NET.
Now that we've gotten that out of the way
# What are the different ways of converting source to machine code?
Although I am aware there are tons of ways to "compile" code, this blog post is not about that, so I'm going to oversimplify it. We can broadly categorise this conversion into 3 different categories:
- Compiling (C, C++)
- Interpreting (Python)
- JIT Compiling (Java, C#)
Compiling - Turn all of your source code into machine code, and store it that way. Advantage? Code is super-fast, since everything is already in a form understood by your machine, and all necessary optimisations have been performed. Disadvantage? Even a small change in your code will warrant a full re-compile of the code to form a new binary, with new optimisations, which is a time consuming and pretty complex process for larger projects consisting of lots of binaries.
Interpreting - Think of this as translator between you and a person that speaks a foreign language, except the person speaking the foreign language is your CPU. There is a layer in the middle that "interprets" each line of your code as it executes in real time, and all checks (except syntax) are performed, and each line is independent of the other. Meaning, if I have a piece of code that looks like this:
1 | for i in range(1000000000): |
The line containing the print statement would get interpreted by the translator 1000000000 different times, without it ever knowing it had just done that a couple nanoseconds back. This is an insane waste of time, because it repeating the same process over and over again, with applying 0 optimisations.
That doesn't sound very nice, no? Why would you not optimise despite knowing that code is being repeated so much?
That brings us to the next mode of conversion: JIT Compiling.
JIT Compiling - JIT (Just In Time) is a method of compilation, most popularly used by Java (Java Virtual Machine), so I will be taking Java as a reference when explaining this.
When the JVM is running, all methods are compiled in a tiered and on a need-basis. They all start out similar to an interpreter, where the JVM directly reads the bytecode of a single line and executes it. The catch, however, is when a specific unit (called the CompilerBroker in the JVM) decides that a method is being invoked very often, it compiles that specific method (known as a "Hot method") into the next tier of compilation (the C1 compiler), and then it is profiled (in order to apply further optimisations), and so on. Essentially, it can be thought of a rainbow land between compiling and interpreting, where code is only compiled on a per-need basis.
So, in order of efficiency - we can arrange the above 3 methods in the following order:Compiling >> JIT Compilation >>> Interpreting
# Okay, what now?
Why did I discuss all this, though? Well, .NET happens to be mainly JIT Compiled, and just like how Java has the JVM (Java Virtual Machine), .NET has the CLR (Common Language Runtime) which handles JITting code.
Through the years, .NET assembly has only contained the IL (Intermediate Language) code, which needs to be compiled and interpreted into its form of native code by the JIT Compiler after the application begins to run. As the .NET framework started expanding its support to more forms of hardware/software platforms, and was capable of building various kinds of applications, a lot of stress was put on Microsoft to improve the performance of the engine as it was the bottleneck for performance of the application as a whole. Some improvements were made, and one such improvement was AOT (Ahead of Time) compiling.
# Down to business
There is a specific form of AOT Compiling, supported from .NET Core 3.0+, called R2R (Ready to Run). In this method, code is compiled and kept ahead of time. This kind of takes a lot of the weight off the runtime engine, since a lot of the code need not be compiled at runtime, and the pre-compiled code can be used instead. A lot of the original factors of the binary, like the metadata, and a bunch of old and new headers are required for this method as well (Why is this important? we'll find out).
This introduces the issue.
The code compiled ahead of time is obviously more efficient/optimal than the code the JIT engine would generate at runtime, and both of them would be more or less the same regardless. In R2R compiling, IL code is still produced, but it is not JIT compiled because the engine is smart enough to recognise and say, "Hey! This (the compiled version of the code I want to execute) is already present, I can just use that!". The IL is only present there for our sake, but is never actually used. And this IL is the code that is used by popular decompilers like DnSpyEx/ILSpy to show us what any given .NET binary might be doing.

Are you seeing the issue yet?
(THE IL CODE WE SEE IS NEVER EVEN BEING USED!!)
So what is really going on?
# Reverse Engineering R2R Stomped code
I will explain with the help of 2 challenges that utilised this very technique: Trompeloeil from Insomni'hack teaser 2024 , and Delirium from AOFCTF 24 (the latter being a challenge made by a friend of mine, hexamine22, which later inspired me to make this blog).
Let's take a look at the second one 1st, Delirium.
Opening up the file in CFF Explorer, and heading over to the .NET Directory , and checking the offset of the ManagedNativeHeader RVA, we can see that adding 8 and checking the DWORD at that location tells us what kind of format this specific dll was compiled in.
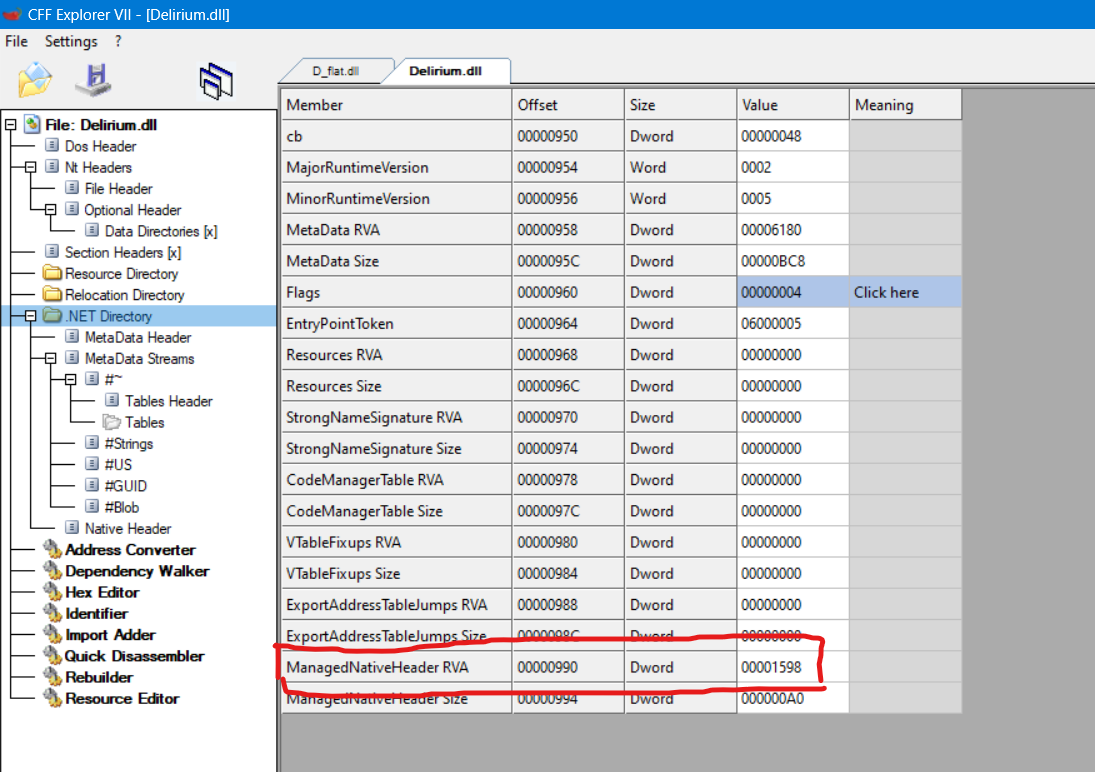
Opening the same offset (+8) in a hex editor like GHEX, we can see this
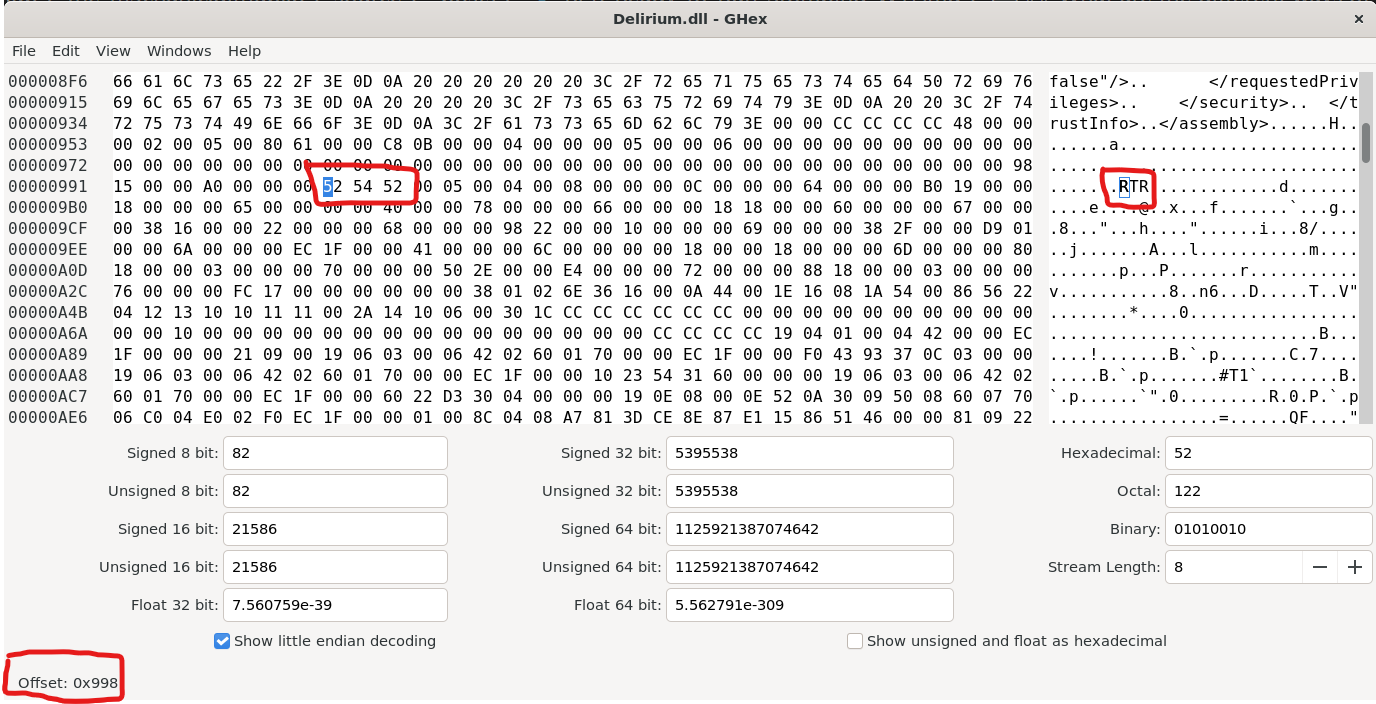
The part we need to focus on here is to see that the value of the DWORD is 0x00525452 ("RTR"), signifying that this dll was compiled in the Ready to Run format.
Opening up the decompiled code in ILSpy, we get something very peculiar:
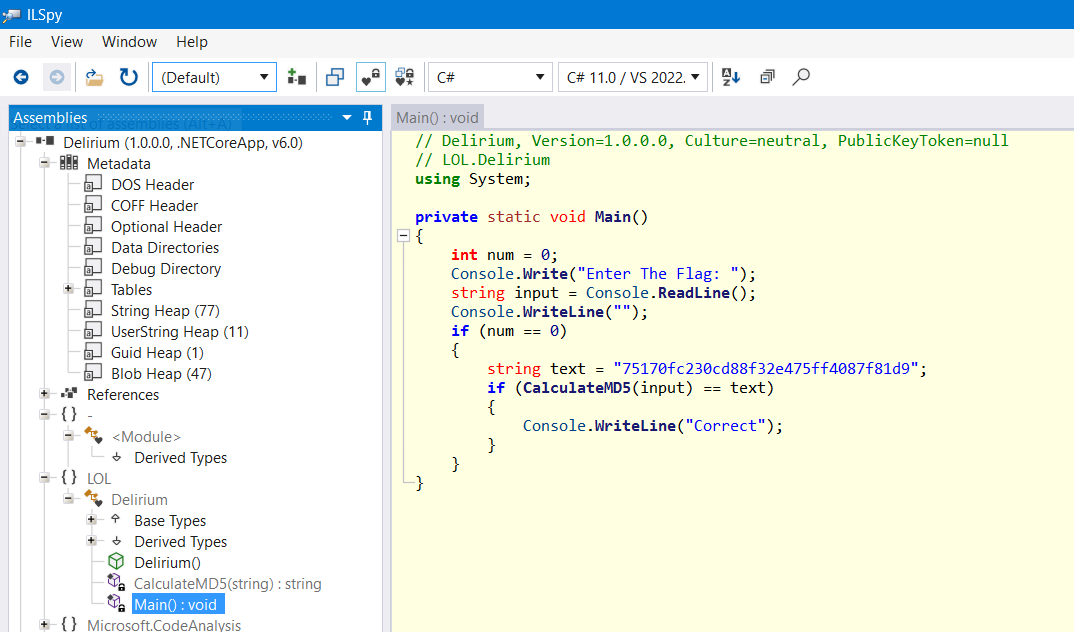
What? Just a md5 hash check for the flag? That doesn't seem right 🤔
A wise man once said...
When in doubt, read the assembly (in this case, the IL will suffice)
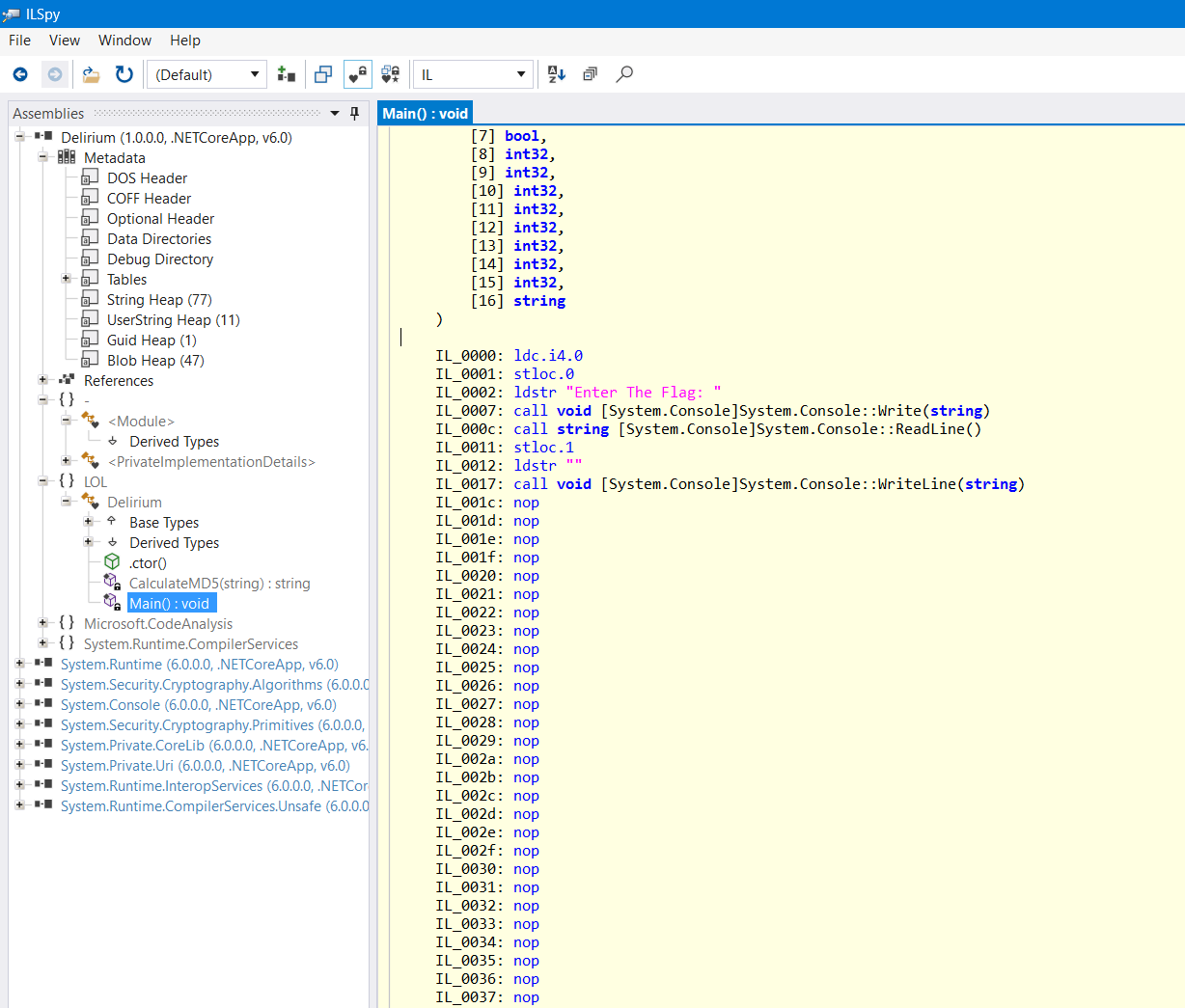

Hmm, looks odd. Why are there so many nop instructions? Something seems wrong here.
Thankfully, ILSpy has an option to show us Ready to Run assembly code (the one that's pre-compiled) for binaries that are compiled that way, and since our binary is an RTR one, it should be available.
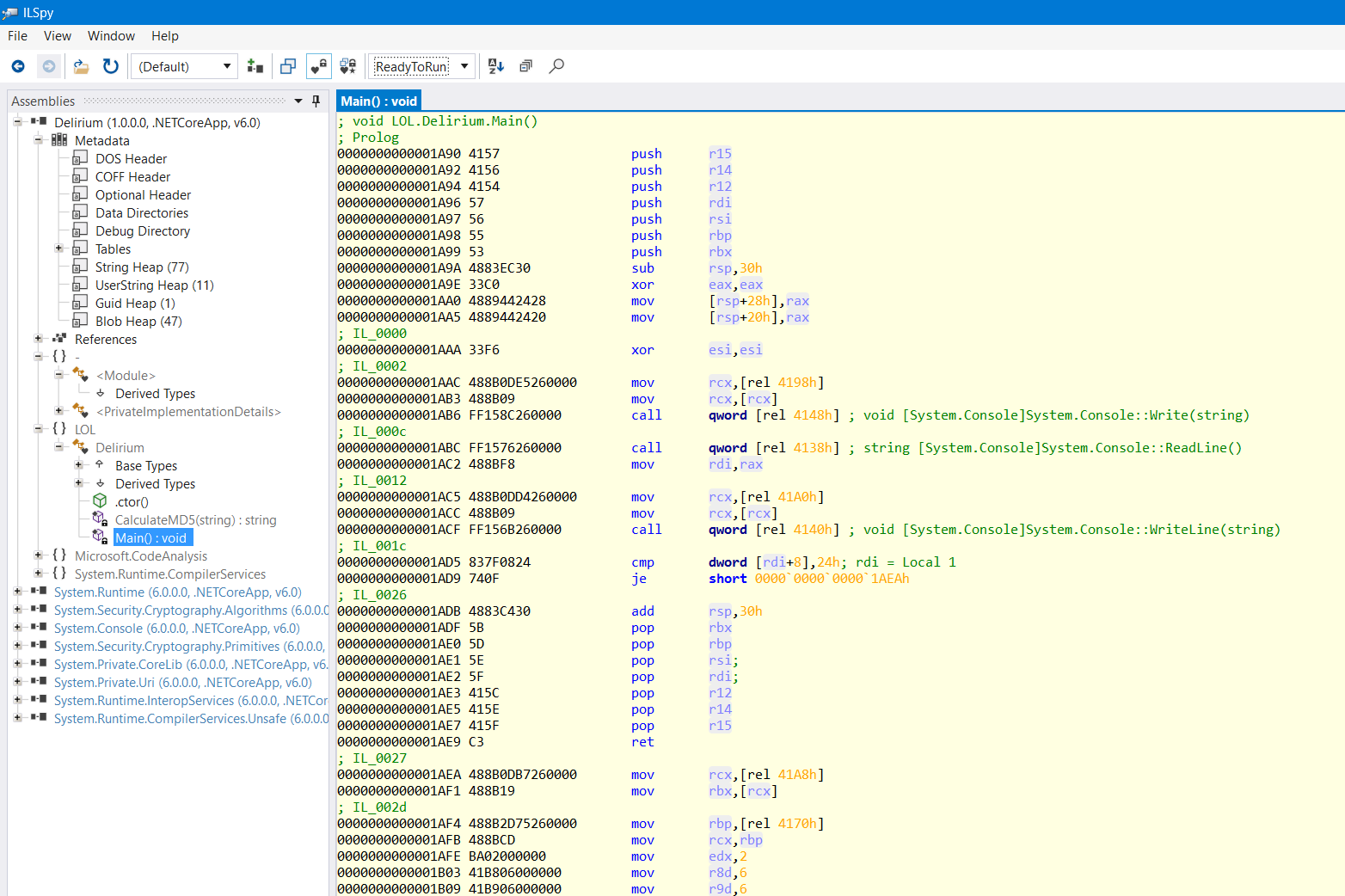
This disassembly is completely different from what the C# decompilation showed us... wtf?
From this, we can conclude one thing:
Given that we can read this assembly, there are multiple ways to progress with solving the challenge now.
- Static analysis - Read the disassembly and figure out what is going on (boring ❌)
- Dynamic analysis - Debug and set a breakpoint at the dll main in IDA (or any debugger of your choice, I prefer IDA), and examine variables at runtime (the method we will be following ✅)
So how do we do that?
We can use this reasoning: The binary asks us for input, and that happens from the dll. Unless the input is entered, none of the actual logic happens, we can be sure of that from the disassembly. So, we can run the Delirium.exe file, and let it run until it stops and asks us for input - that is when we can be sure that the control flow has switched over to the DLL.
Let us do that first.
(Note: If you come across any exceptions being generated when letting the exe run, just pass them to the application. Those are general exceptions that come from control flow switching between different threads in the presence of a debugger)
Now we need to find our dll main.
View > Open Subviews > Segments will show us every segment of every file currently loaded
Search for Delirium.dll among those, and look for the CODE section in those.

With some quick pwntools, we can grep for the bytes of the first couple of instructions of our dll's main.
1 | from pwn import * |
Once you get to the start of the CODE section of the dll (the 1st one if more than one exist), simply click Alt+b in IDA (to search for bytes), and paste "AWAVATWVU" (with the quotes, since it's a byte string). Of all the results that show up, click on the one that are present in Delirium.dll .
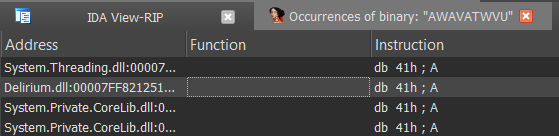
Double-clicking will lead you to a bunch of bytes, but that is only because IDA is interpreting those bytes as data, and not code. To tell it to read them as code, put your mouse over there and hit C (convert to code).
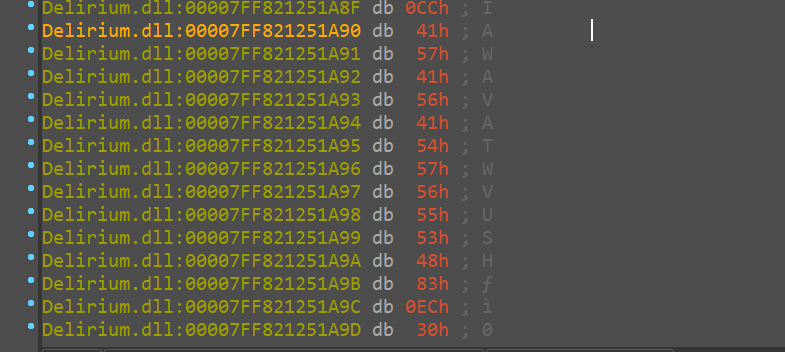
After hitting c
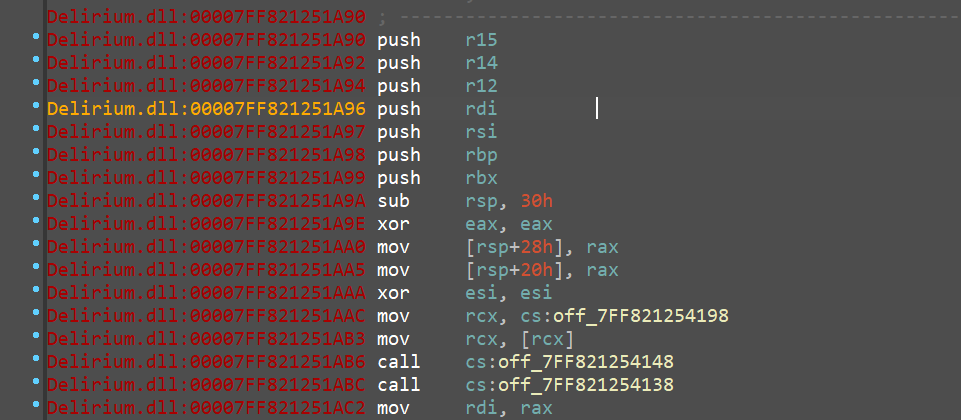
And to be able to decompile this assembly, IDA needs to see this code block as a function, so place your cursor at the start of the code block, and hit P (mark start of function).
Then you should be able to decompile.
Although, since none of the symbols are resolved, we won't know the names of the native libraries being called, so we'll have to make sense of things for ourselves.
After a bit of debugging and reversing, we can find that this challenge is pretty easy - it takes your input, XORs it with a predefined text, and multiplies it with another matrix and checks with a predefined matrix. Pretty simple stuff to reverse.
Now, we seem to have a fixed way of dealing with binaries like this, here's a recap:
- Confirm R2R mode through offset
- Open up in ILSpy
- Grab bytes of starting few instructions of "stomped code"
- Run binary in IDA until it stops for input
- Locate dll segment in IDA
- Search for said bytes in IDA
- Mark code
- Mark function
- Decompile
- Profit!
# Asserting dominance over R2R compiled binaires
Let us try this approach on another binary, Trompeloeil from Insomni'hack teaser 2024
First, grab the offset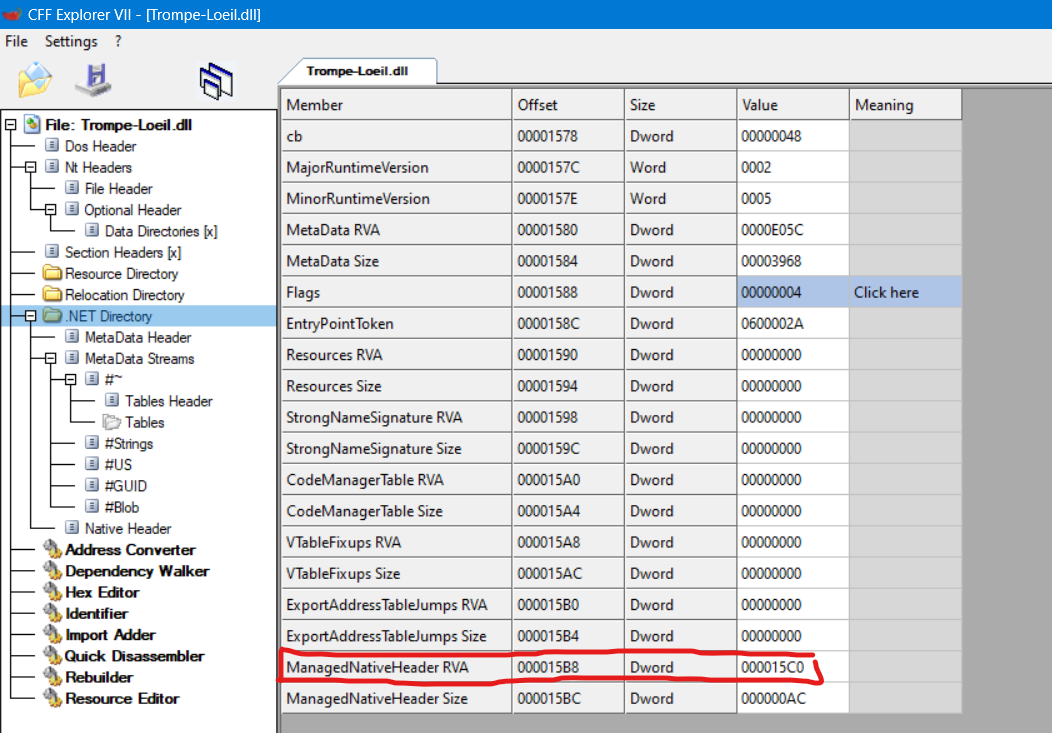
Next, check if it's in "RTR" mode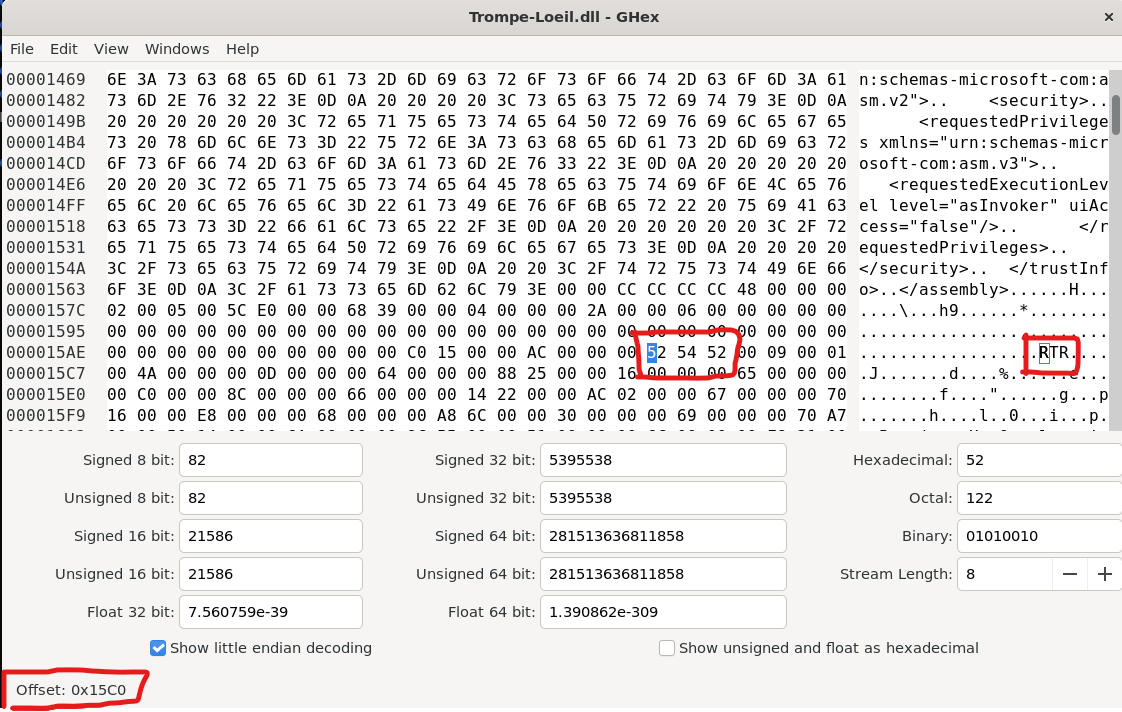
(Note: You can also do a quick confirmation to make sure things look suspicious, like here for example)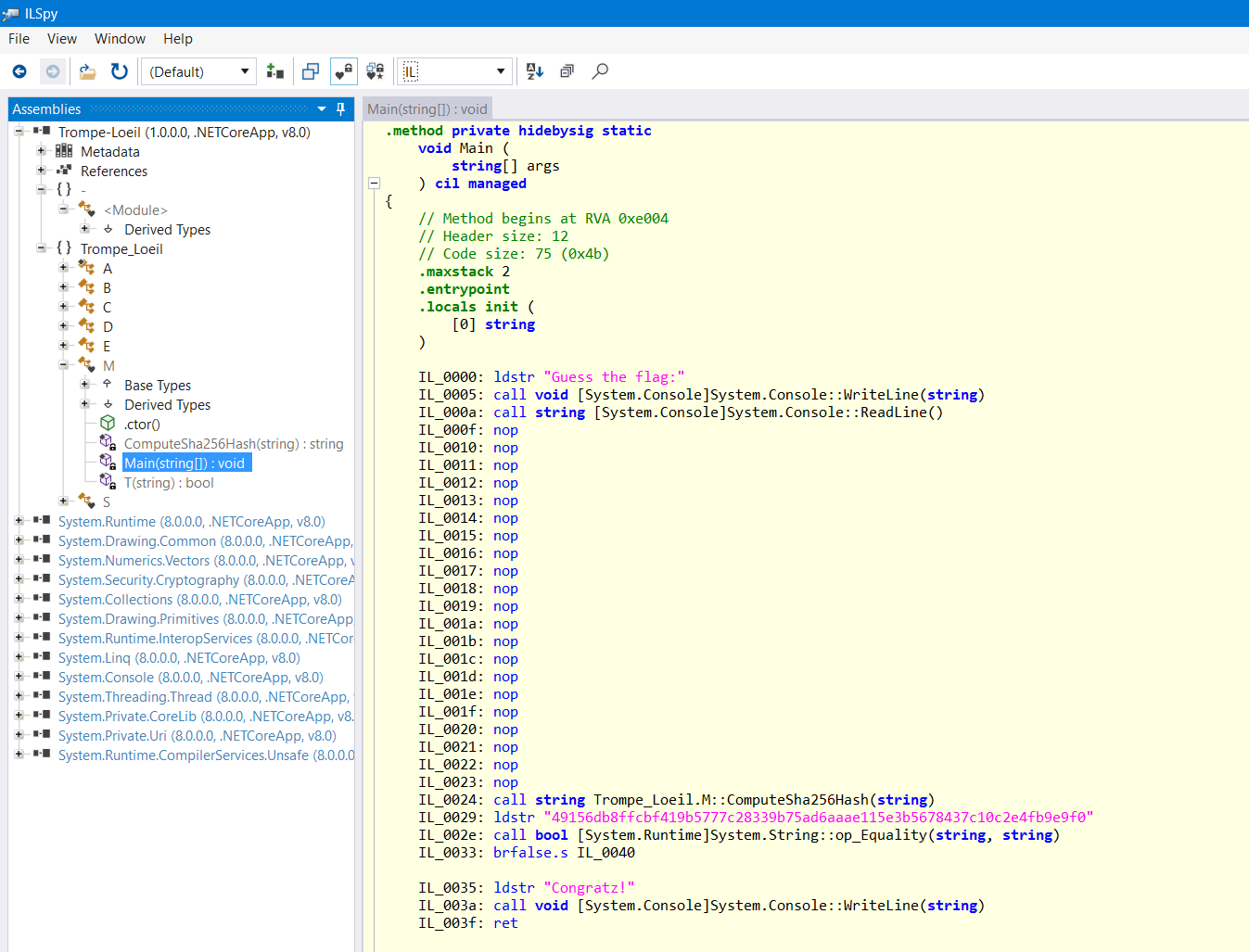
Too many nops, like last time
Grab the first few bytes of the function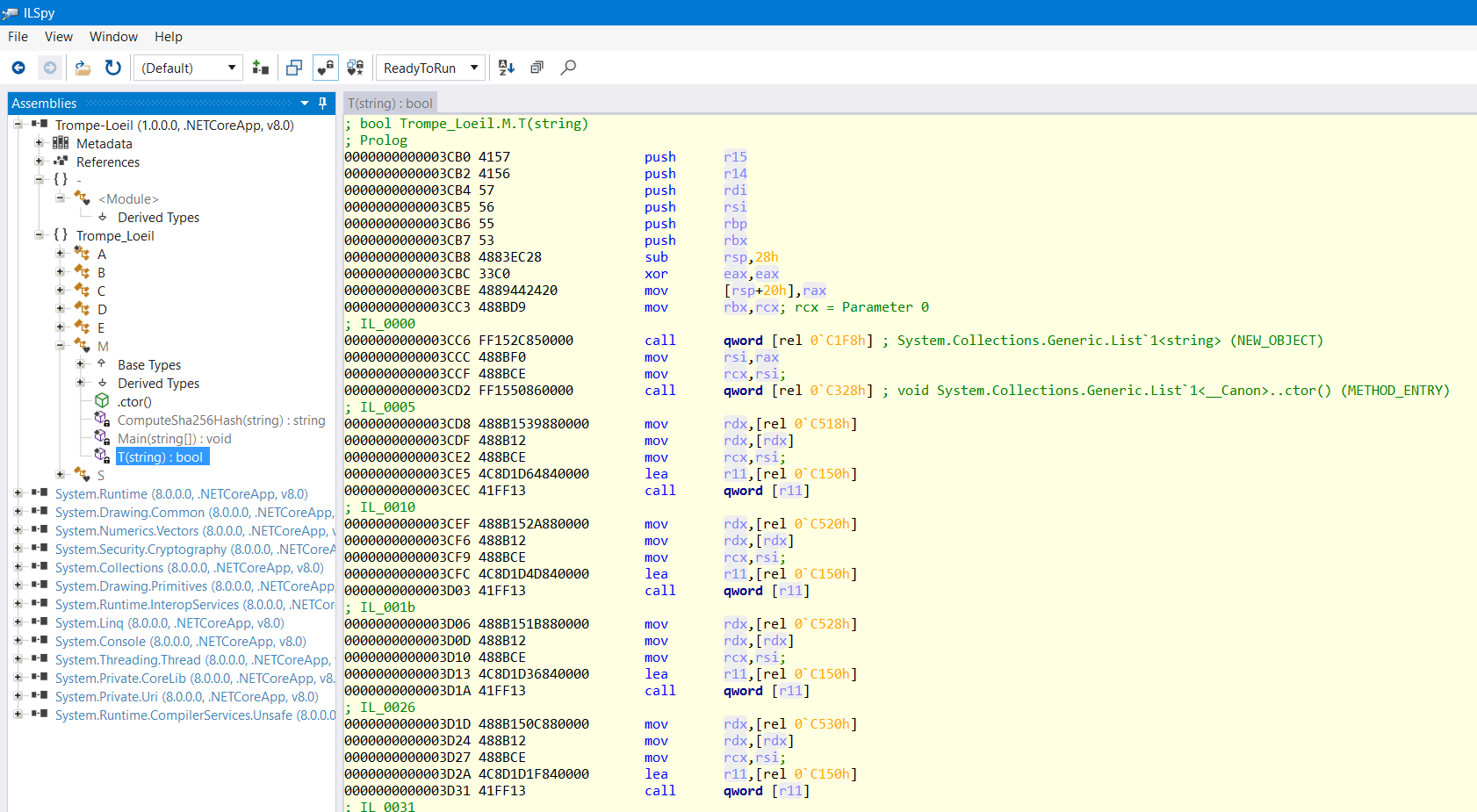
Look for the CODE section of the dll segment in IDA
Start your search from there.
Most likely, you'll have multiple results, but only one that corresponds to your dll, catch that one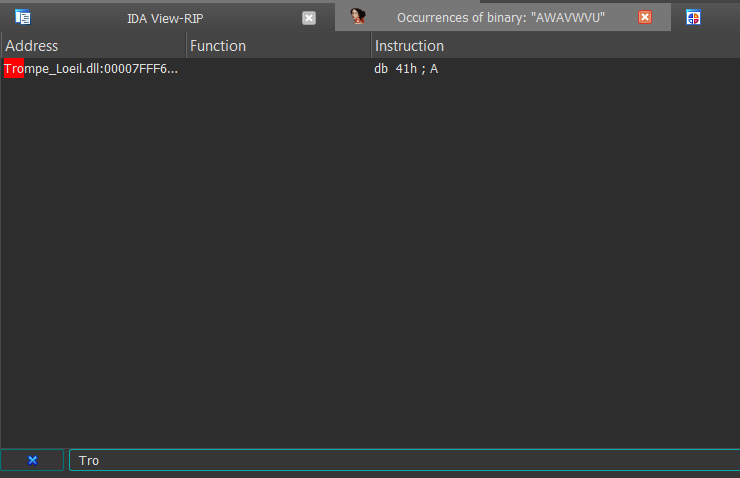
Convert to code (hit C)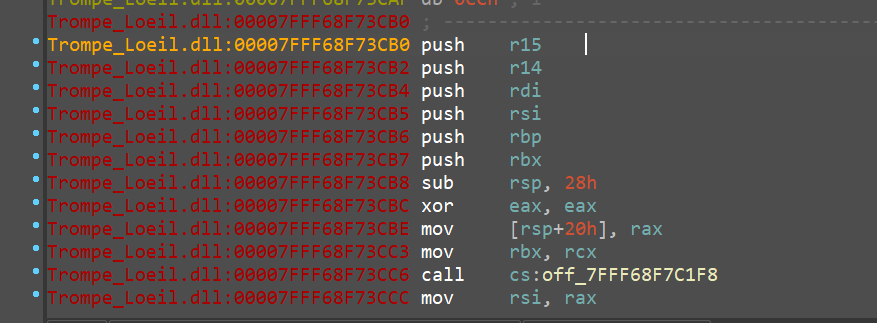
Mark as function (hit P)
Decompile!
Congratulations, you have successfully Reverse-Engineered an R2R obfuscated binary. You can give yourself upto 2 pats on the back.

All in all, this is an interesting and novel way to hide what you're doing in your .NET binary. Very fascinating approach, and if you guys have any doubts with regards to anything I've mentioned here - you can always reach on Twitter. Cheers.