Me, Chandra and Sidharth recently placed 3rd in a Reverse Engineering Hackathon/CTF conducted by IIT Madras and IIITDM Kancheepuram. This was very unique as it wasn't like any of the other RE focused CTFs we've played before and the style was really different.
The entire thing began with a CTF which had all categories you would expect in a normal CTF (RE, Pwn, Web, Forensics). Us being low level guys, managed to get down RE and Pwn, and took a bit of time with Forensics. Sadly Web was too guessy for us 😔 (blind + skill issue). They froze the scoreboard like 30 mins into the CTF but I figure we qualified since they sent us a mail for the next round.
After the prelims CTF, I think the top 25-30 teams were picked for the next round. The next round was a RE specific CTF. That one was super easy except for one challenge which was broken, I think. They pushed a fix for it and then we solved that too. So far it was looking pretty normal and we weren't sure what the "hackathon" part of this was.
For context, a Hackathon is a software engineering/development oriented competition wherein teams are given certain topics/themes and guidelines to follow, and they have X amount of time to build a working product or a prototype, which they can then showcase to the judges and based on the judgement received they would get credited a certain number of points.
So after the 2 prelim rounds of CTFs, 20-25 teams were picked for the Hackathon (aka "Defense") phase. This is where the uniqueness of the entire thing began. We were given a document that outlined what we would need to do and the specifications we were allowed to use. The entire specification is here.
TL;DR
We are given a main.c file, with 3 sensitive values: key (a 16-byte AES Key), egg_params (a 5x6 array) and a function compute_gf()
Each team is given the same core binary with the above 3 things changed
You "defend" your binary by obfuscating it such that the 3 sensitive values are hard to recover
You "attack" other binaries by reversing and getting those 3 values, and submit them as flags
In the defense phase, we were given criterion to follow with which we were to obfuscate our binaries. These were pretty basic, like:
No using any off the shelf obfuscators like UPX, CobaltStrike, etc.
Code must be written by members of our team, and no one else
The obfuscated binary must be functionally the same as the original, etc.
Okay.. enough yap This blog is more to focus on one of the challenges made by some folks at InfosecIITR.
They made an LLVM based obfuscator, and while our challenge was something similar, it followed a different style from theirs. We went for a control flow flattening approach - while they went for more of a instruction overlap approach. It was an easy challenge, but I just wanted to showcase some cool things IDAPython is capable of.
The binary itself had a behaviour exactly the same as the others in the competition - give it plaintext as a command line argument, and it would encrypt it and give it back to you.
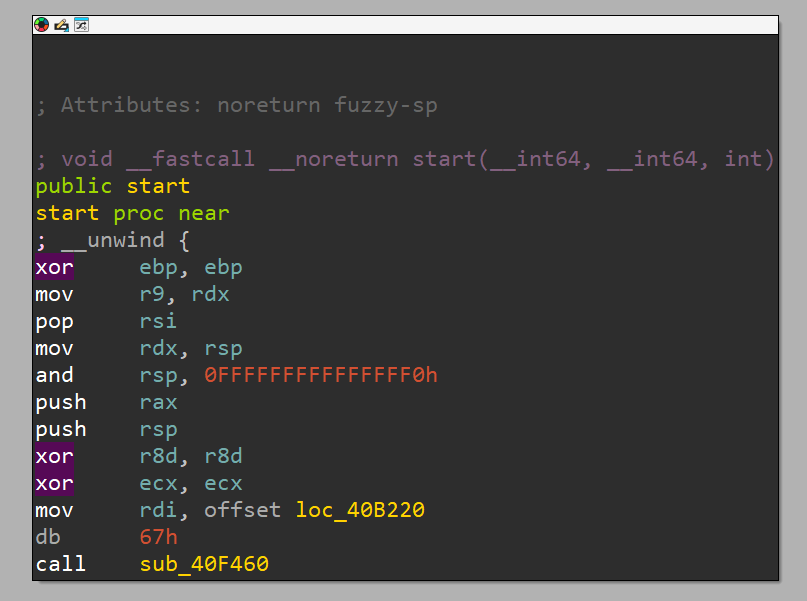
Now, looking at it in IDA, I wouldn't say it was the prettiest binary I've ever seen. If you look for the main function in the normal Linux ELF method (look for start , then find the first argument passed to the function - libc_start_main - which is explicitly called by start), you will first off see that IDA marks it as a location and not a subroutine - meaning that something is off already.
And at the location:
That definitely does not look right.
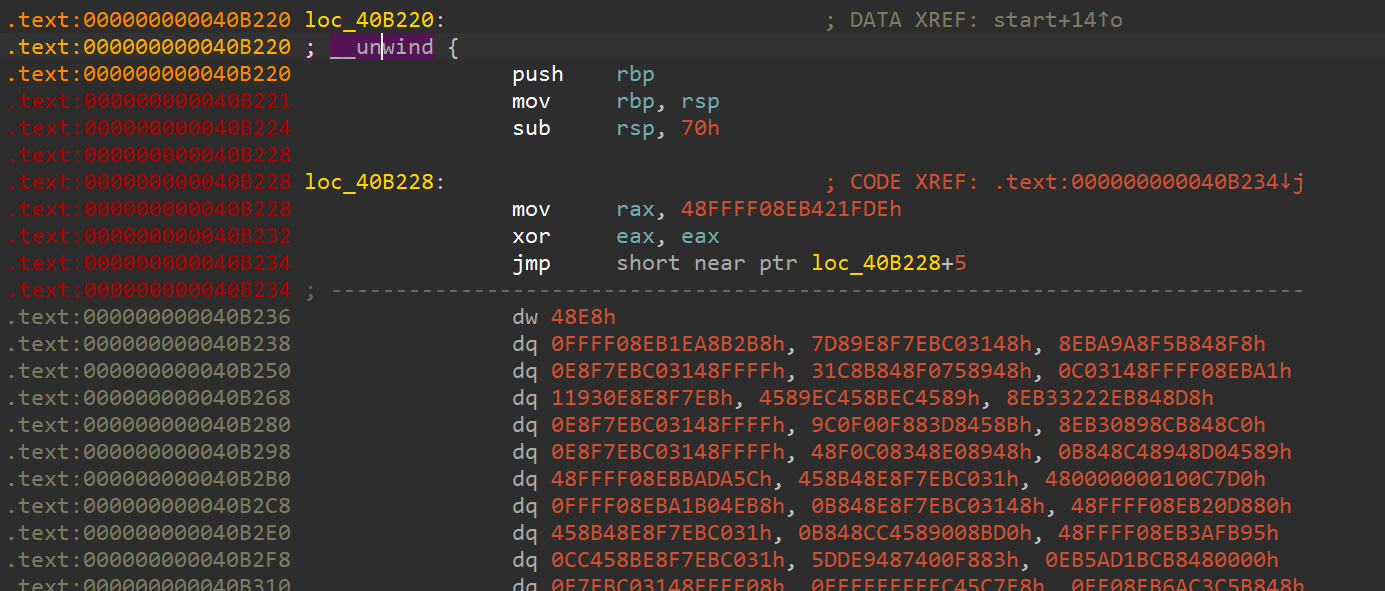
The jmp at 0x40B234 definitely looks suspicious, why is it jumping to the address of its own basic block + 5?
You can press u to undefine code at a given position in IDA, and c to redefine it as code. Let us undefine code starting from 0x40B228 , and defone code starting at 0x40B228 + 5 -> 0x40B22D , and see where that takes us.
Looks like the code there is being interpreted as data, we can fix that easily (hit u at that address and then hit c ). Doing so, gives us this
Well well well, what do we have here? A hidden jmp instruction.
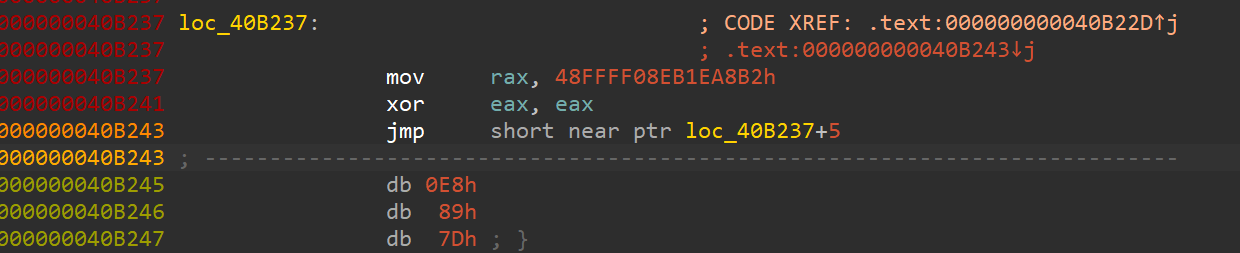
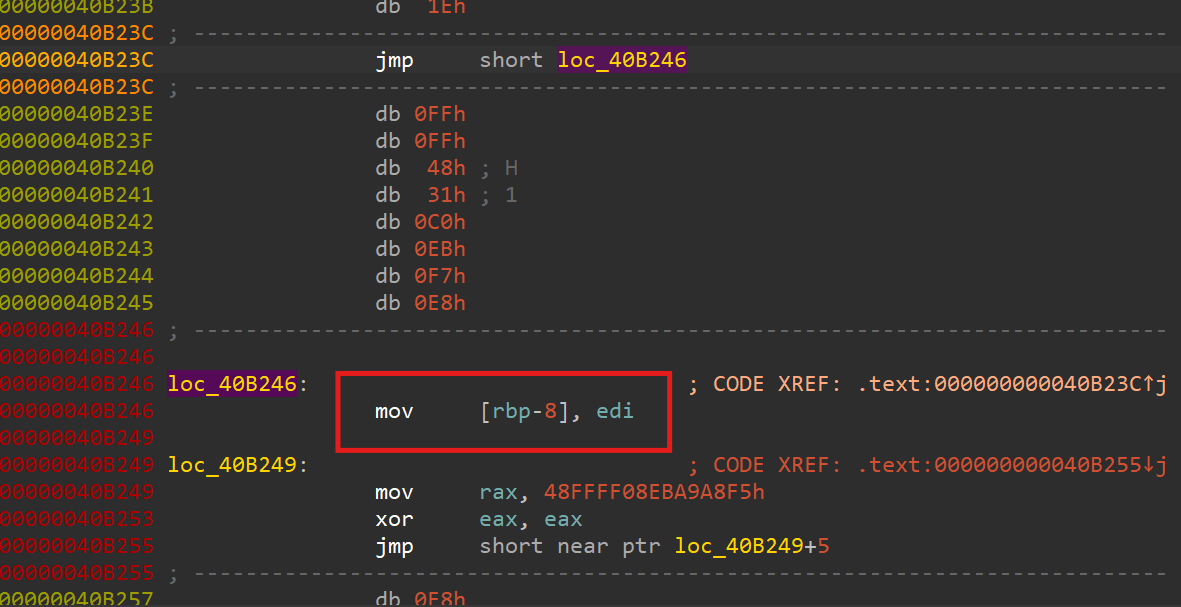
Analysing the code at that location gives us similar looking stuff
Applying the same stuff again, gives us the same results, except an instruction before the same old block again
Again, with this jmp leading to a similar looking block, i.e:
mov a random 8-byte value into rax
xor eax, eax
jmp into a location which is 5 bytes ahead of the basic block it belongs to, which will jump to a new location which may/may not have some code there, before it enters the same block again.
At this point in the competition the pattern was clear to me, and I started figuring out a way to extract just the instructions we need (between the real jmp and before the next obfuscated block). So I settled on writing down an IDAPython script for this, since I work mainly with IDA Pro anyways.
My idea was this:
Look for instructions matching the format mentioned above
If the instruction is found, then find the 5th byte offset from the start of the block, and extract the address of the real jmp from on there
At the new jmp address, keep reading instructions until you meet the next instruction matching the block
Rinse. Repeat.
I wanted to take this as a chance to check out how good IDA's Python API was, and basically take it on a test drive.
Now I had to write an IDA Script to this (🗿), ahem, so we shall do that next
The IDA Python documentation isn't exactly the best (if someone actually does find something, please hit me up), so I kind of had to rely mostly on grep.app to see examples of stuff similar to what I want to do.
Some time of dilly dallying, and I made a rough script to fix up the main function.
# now we know for sure it is a messed instruction # calculate the jump address jmp_insn = ida_ua.insn_t() jmp_insn_len = ida_ua.decode_insn(jmp_insn, call_loc+12)
if jmp_insn_len == 0or jmp_insn.get_canon_mnem() != 'jmp': returnFalse
# jmp address - return as an integer, not a hex string jmp_addr = jmp_insn.Op1.addr print(f"jmp_addr = {hex(jmp_addr)}") returnTrue, jmp_addr, jmp_addr - call_loc
# initialize register map reg_map = get_register_map() for i inrange(8): if i in reg_map: reg_map[i] = 'r' + reg_map[i]
while curr_addr < end_addr: result = is_messed_instruction(curr_addr)
if result: is_messed, jmp_addr, length = result
print(f"Found messed instruction at {hex(curr_addr)}, jumping to {hex(jmp_addr)}")
# NOP out the bogus instruction for i inrange(5): idc.patch_byte(curr_addr + i, 0x90)
# skip the next 5 bytes curr_addr += 5
# force create an instruction at the jump address in idb idc.create_insn(jmp_addr)
# decode the instruction at the jump address so we can get the new jump address (chain basically) jmp_insn = ida_ua.insn_t() jmp_insn_len = ida_ua.decode_insn(jmp_insn, jmp_addr)
# NOP out the bogus instruction range_len = jmp_chain_addr - jmp_addr for i inrange(range_len): idc.patch_byte(jmp_addr + i, 0x90) else: print(f"No valid jump instruction at {hex(jmp_addr)}") else: print(f"No messed instruction found at {hex(curr_addr)}")
Soon after this, I wanted to fix up the entire binary - whichever functions were being called that is. So I went with a DFS approach. From main, make a list of all the functions being called from inside it. Subsequently, add those to the "deobfuscation" queue. Likewise, keep going until there are no functions left.
Also one annoying thing is inside IDA's API, all the instructions and registers are stored using codes instead of their actual names. I found that the method I've used in my script works for most cases.
# now we know for sure it is a messed instruction # calculate the jump address jmp_insn = ida_ua.insn_t() jmp_insn_len = ida_ua.decode_insn(jmp_insn, call_loc+12)
if jmp_insn_len == 0or jmp_insn.get_canon_mnem() != 'jmp': returnFalse
# jmp address - return as an integer, not a hex string jmp_addr = jmp_insn.Op1.addr print(f"jmp_addr = {hex(jmp_addr)}") returnTrue, jmp_addr, jmp_addr - call_loc
defdeobfuscate_function(start_addr, end_addr=None): """ deobfuscate a function from start_addr to end_addr. if end_addr is not provided, use the function's end address. """ print(f"Deobfuscating function at {hex(start_addr)}") # if end_addr is not provided, try to get it from IDA if end_addr isNone: func = ida_funcs.get_func(start_addr) if func: end_addr = func.end_ea else: print(f"Warning: Could not determine end address for function at {hex(start_addr)}") # try to find the next function and use its start as our end next_func = ida_funcs.get_next_func(start_addr) if next_func: end_addr = next_func.start_ea else: print(f"Error: Cannot determine end address for function at {hex(start_addr)}") return print(f"function bounds: {hex(start_addr)} - {hex(end_addr)}") # queue for functions to deobfuscate (DFS) functions_to_process = [] curr_addr = start_addr while curr_addr < end_addr: # check if it's a "messed" instruction result = is_messed_instruction(curr_addr) if result: is_messed, jmp_addr, length = result print(f"Found messed instruction at {hex(curr_addr)}, jumping to {hex(jmp_addr)}") # NOP out the bogus instruction for i inrange(5): idc.patch_byte(curr_addr + i, 0x90) # skip the next 5 bytes curr_addr += 5 # force create an instruction at the jump address in IDB idc.create_insn(jmp_addr) # decode the instruction at the jump address so we can get the new jump address (chain basically) jmp_insn = ida_ua.insn_t() jmp_insn_len = ida_ua.decode_insn(jmp_insn, jmp_addr) if jmp_insn_len > 0and jmp_insn.get_canon_mnem() == 'jmp': jmp_chain_addr = jmp_insn.Op1.addr print(f"jmp_chain_addr = {hex(jmp_chain_addr)}") # NOP out the bogus instruction range_len = jmp_chain_addr - jmp_addr for i inrange(range_len): idc.patch_byte(jmp_addr + i, 0x90) else: print(f"No valid jump instruction at {hex(jmp_addr)}") else: # check if it's a call instruction insn = ida_ua.insn_t() insn_len = ida_ua.decode_insn(insn, curr_addr) if insn_len > 0and insn.get_canon_mnem() == 'call': # get the callee if insn.Op1.type == ida_ua.o_near: call_target = insn.Op1.addr print(f"Found call at {hex(curr_addr)} to {hex(call_target)}") # add the target to our list of functions to process if call_target notin [f[0] for f in functions_to_process]: # check if it's a valid function func = ida_funcs.get_func(call_target) if func: functions_to_process.append((call_target, func.end_ea)) else: # try and create a function if ida_funcs.add_func(call_target): func = ida_funcs.get_func(call_target) if func: functions_to_process.append((call_target, func.end_ea)) else: print(f"Warning: Could not create function at {hex(call_target)}") # still add it to the queue, we'll try to determine bounds later functions_to_process.append((call_target, None)) else: print(f"Warning: Could not create function at {hex(call_target)}") # still add it to the queue, we'll try to determine bounds later functions_to_process.append((call_target, None)) if insn_len > 0: curr_addr += insn_len else: curr_addr += 1 return functions_to_process
reg_map = get_register_map() for i inrange(8): if i in reg_map: reg_map[i] = 'r' + reg_map[i]
main_start = 0x40B220 main_end = 0x40BC20
processed_functions = set()
function_queue = deque([(main_start, main_end)])
while function_queue: start_addr, end_addr = function_queue.popleft() if start_addr in processed_functions: continue # mark the function as processed if not alr processed processed_functions.add(start_addr) new_functions = deobfuscate_function(start_addr, end_addr) # add new functions to the queue if new_functions: for func_start, func_end in new_functions: if func_start notin processed_functions: function_queue.append((func_start, func_end))
This will fix up the entire binary, although you might have to manually fix up some function boundaries by yourself. You can do that by right clicking anywhere inside the function/subroutine already defined.
The script is kinda massive but I tried my best to make it as clean as possible so I can reuse parts of it later, hopefully someone shows me some goated IDA Python script snippets that are out there somewhere 🙏
Thank you for reading this super-hurried post! If you have any questions or if I have made any errors, please reach out to me on Twitter/X 😄